- 全部
- data visualization2
- fintec4
- scorecard3
- hexo4
- 默认分类0
- deep learning3
- machine learning6
- paper1
- recommender system1
- natural language processing1
- datawhale1
- competition3
- python9
- graph neural network1
-
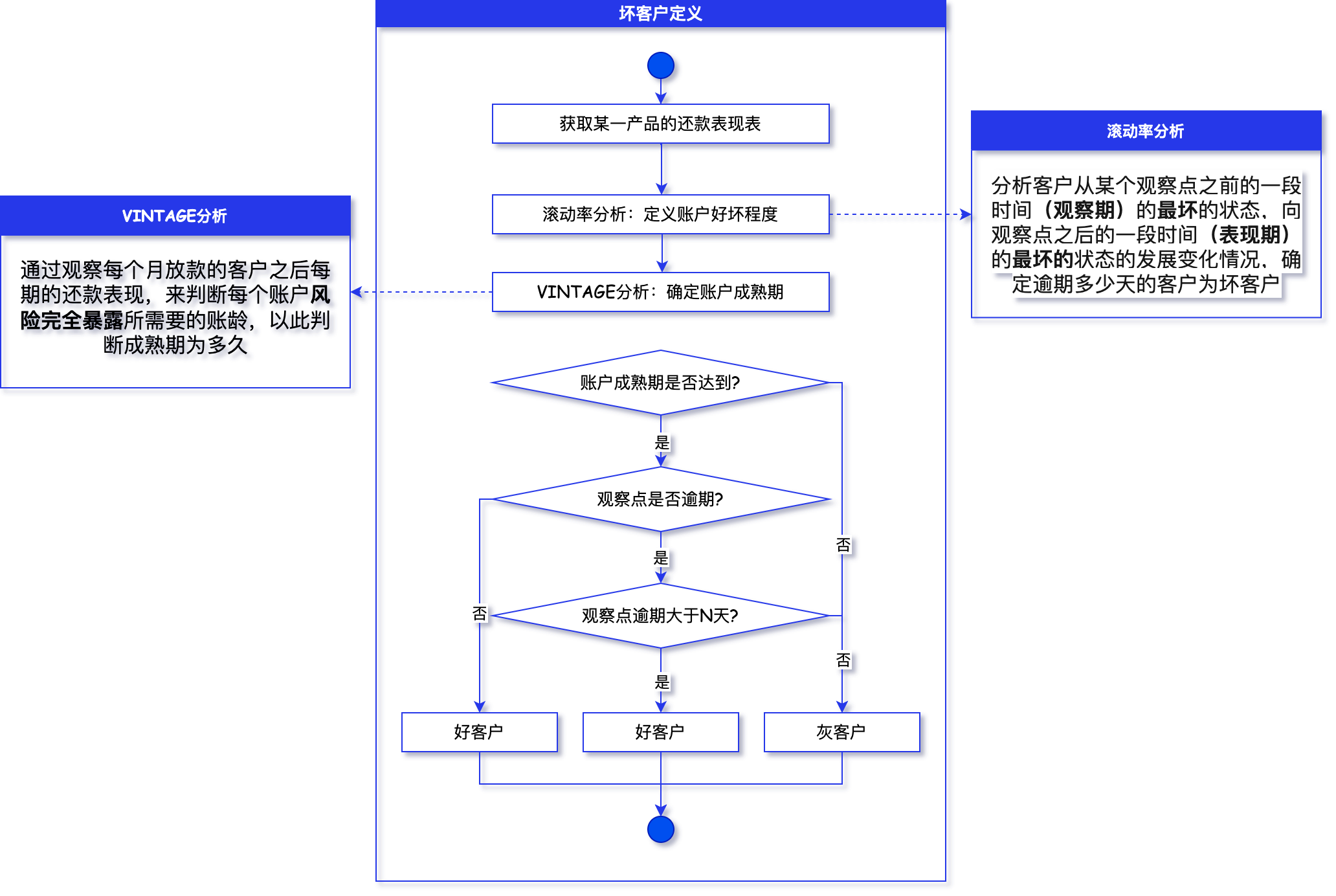
 ITLubber酱发布于 October 24,2023
ITLubber酱发布于 October 24,2023
-

金融风控数据挖掘之策略自动挖掘方法
ITLubber酱发布于 May 19,2023
-

风控评分卡端到端建模
ITLubber酱发布于 February 03,2023
- 1